
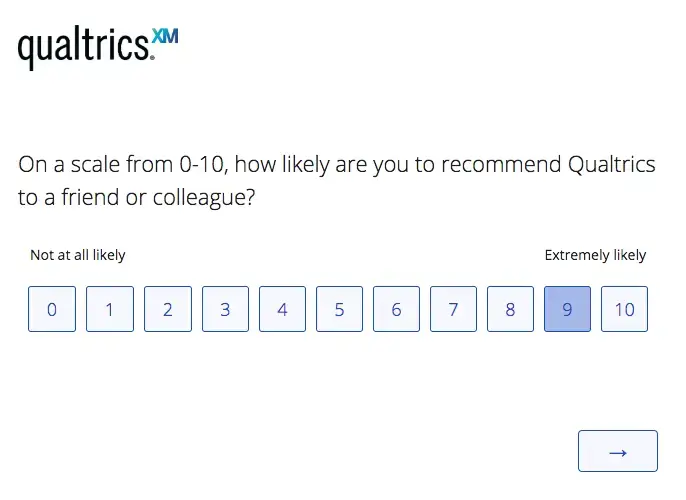
The NPS Question as written in an article published about NPS by Qualtrics.

An intentionally silly, low-fidelity recreation of conversations with senior leadership about CX metrics

I owe my growth managing senior and C-level stakeholder expectations to my manager's mentorship

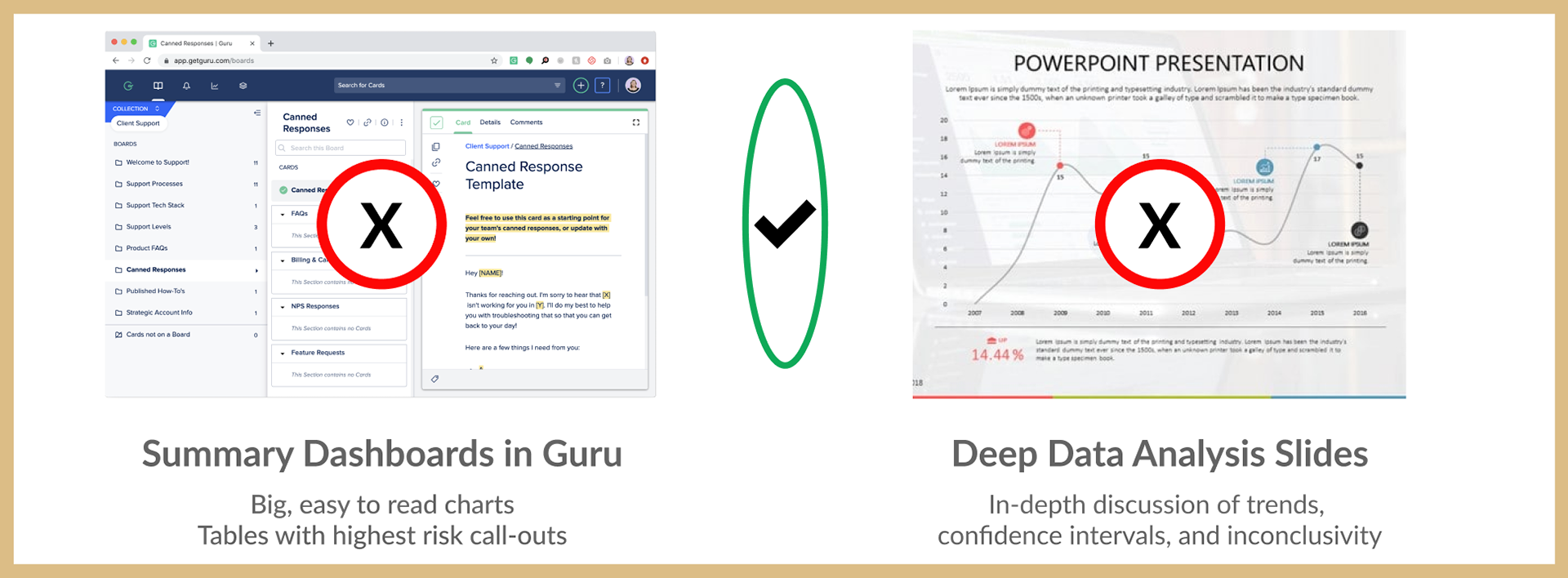
Summary Dashboards in Guru were too vague and lacked a call to action. Deep Data Analysis felt too much like a lecture, sucking the air out of the room for conversation. There had to be a "just right" middle ground.
Different themes had different frequencies (horizontal) and severities (vertical). This graphical representation of thematic impact would help argue which themes were important to address.
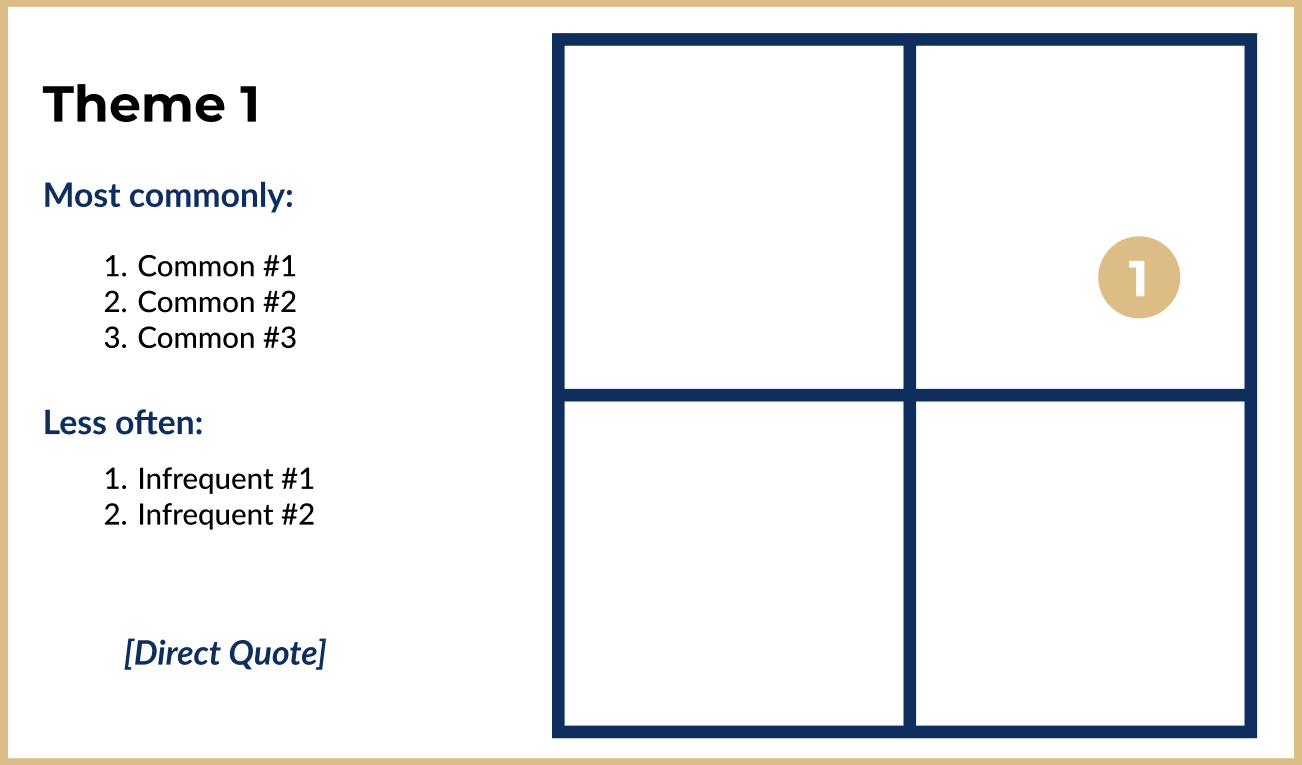
This is an example of one of the slides I presented to Operational Leadership at Flexcar - of course, the themes and quotes were filled in. They're removed for the sake of confidentiality.

I introduced all four theme-groups in a simplified frequency/severity matrix... but arguments could be made for focusing on Theme 1 or Theme 2. I believed Theme 1 was more impactful.

Because I kept the initial framework simple to introduce the concepts, I had the attention of stakeholders. Breaking the framework to make my point took stakeholder interactions from attention to buy-in and trust.